

LLM چیست؟ مدل زبانی بزرگ به زبان ساده، همراه با مثال و کاربرد


در این مقاله میخوانید
- مدل زبانی بزرگ یا LLM چیست؟
- LLM چطور کار میکند؟
- کاربردهای عملی LLM در زندگی و کسبوکار
- مزایای LLM چیست؟
- انواع مدلهای زبانی بزرگ یا LLM
- مقایسه سریع انواع LLM
- مثالهای معروف LLM که هر روز با آن سروکار دارید!
- چالشها و محدودیتهای LLM و راهحلهای آن
- آینده LLM چیست؟ چه تغییراتی در انتظار ما است؟
- جمعبندی
- سوالات متداول
مدلهای زبانی بزرگ یا LLMها این روزها به عنوان مغز متفکر هوش مصنوعی شناخته میشوند که توانایی درک، تحلیل و تولید زبان انسان را دارند. این مدلها نه تنها حجم زیادی از دادهها را پردازش میکنند، بلکه قادرند الگوهای پیچیده زبان، معنا و روابط بین کلمات را شناسایی و متنی طبیعی و قابل فهم تولید کنند. از نوشتن ایمیل و تولید محتوا گرفته تا تحلیل دادهها، پشتیبانی مشتری و حتی کمک به تصمیمگیریهای حرفهای، LLMها تحول عظیمی در زندگی روزمره و کسبوکارها ایجاد کردهاند. در این مقاله از بخش اخبار فناوری در سایت پارسپک، به تاریخچه، ساختار و کاربردهای عملی LLM و چالشهای آن به صورت ساده و جامع میپردازیم تا درک درستی از این فناوری پیشرفته پیدا کنید.
مدل زبانی بزرگ یا LLM چیست؟
مدل زبانی بزرگ (Large Language Model – LLM) نوعی برنامه هوش مصنوعی است که میتواند متن را درک و سپس تحلیل و تولید کند. کلمه بزرگ به این دلیل انتخاب شده که این مدلها با حجم زیادی از دادهها آموزش میبینند؛ دادههایی شامل میلیاردها کلمه از منابع مختلف. هسته اصلی LLMها بر پایه یادگیری ماشین (Machine Learning) ساخته شده و معماری اصلی آنها نیز نوعی شبکه عصبی به نام ترنسفورمر (Transformer) است.
برای آشنایی دقیقتر با هوشمصنوعی مقاله زیر را بخوانید:
اگر بخواهیم سادهتر توضیح دهیم LLM یک برنامه کامپیوتری است که آنقدر نمونه متن، گفتار یا دادههای پیچیده دریافت کرده که میتواند زبان انسان را بفهمد، الگوهای آن را تشخیص دهد و مشابه آن تولید کند. بسیاری از این مدلها با دادههایی آموزش میبینند که از سراسر اینترنت جمعآوری شدهاند (گاهی در مقیاس چند میلیون گیگابایت). برخی مدلها حتی بعد از آموزش اولیه نیز برای بهروزرسانی و توسعه تواناییهای خود، همچنان وب را خزیده و دادههای جدید جمعآوری میکنند.
البته کیفیت دادههای آموزشی اهمیت زیادی دارد؛ هرچه دادههای ورودی بهتر و دقیقتر باشند، مدل نیز زبان طبیعی را با دقت بالاتری یاد میگیرد. به همین دلیل، بسیاری از توسعهدهندگان در ابتدا از مجموعهدادههای پالایششده و کنترلشده استفاده میکنند تا مدل پایه باکیفیتتری ساخته شود.
| دوره زمانی | رویدادها و پیشرفتهای کلیدی | توضیحات |
|---|---|---|
| دهههای اولیه پردازش زبان طبیعی | سیستمهای مبتنی بر قواعد و روشهای آماری | این مدلها فقط الگوهای ساده و محلی را شناسایی میکردند و توانایی درک وابستگیهای طولانی یا معناهای عمیق را نداشتند. |
| اوایل دهه ۲۰۱۰ | ظهور بردارهای معنایی مانند Word2Vec و GloVe | کلمات بهصورت بردارهای عددی در فضای پیوسته نمایش داده شدند و امکان یادگیری روابط معنایی توسط مدلها فراهم شد. |
| سالهای ۲۰۱۰ تا ۲۰۱۶ | شکلگیری مدلهای ترتیبی مثل RNN و LSTM | این معماریها توانایی پردازش دادههای دنبالهدار را بهبود دادند، هرچند مشکل وابستگیهای بلندمدت را بهطور کامل حل نمیکردند. |
| سال ۲۰۱۷ | معرفی معماری ترنسفورمر با مقالهی «Attention Is All You Need» | این ساختار نقطهی عطفی ایجاد کرد و امکان آموزش مدلها روی مجموعهدادههای بسیار بزرگ را فراهم کرد. |
| سال ۲۰۱۸ | انتشار مدل BERT توسط گوگل (معماری Encoder) | قدرت بالای ترنسفورمرها در درک زبان طبیعی در این مدل بهخوبی نمایش داده شد. |
| سالهای ۲۰۱۸ تا ۲۰۲۰ | معرفی سری GPT توسط OpenAI (معماری Decoder) | این مدلها تمرکز خود را بر تولید متن گذاشتند و مدل GPT-۲ بهواسطه تولید متن منسجم مطرح شد. با انتشار GPT-۳ و پارامترهای بسیار زیاد آن، جایگاه LLMها تثبیت شد. |
| سالهای ۲۰۱۹ تا ۲۰۲۰ | عرضه مدلهای Encoder–Decoder مانند T5 و BART | این معماریها قدرت بالایی برای وظایف تبدیل متن مانند ترجمه، خلاصهسازی و بازنویسی فراهم کردند. |
| سالهای ۲۰۲۳ تا ۲۰۲۴ | ظهور معماریهای جدید مثل Mamba و Diffusion LLMs | مدلهای مامبا با تکیه بر ساختارهای State-Space توانایی یادگیری وابستگیهای بلندمدت را با کارایی بیشتر فراهم کردند و مدلهای دیفیوژن نیز با حذف تدریجی نویز متن قابلقبول تولید میکردند. |
LLM چطور کار میکند؟
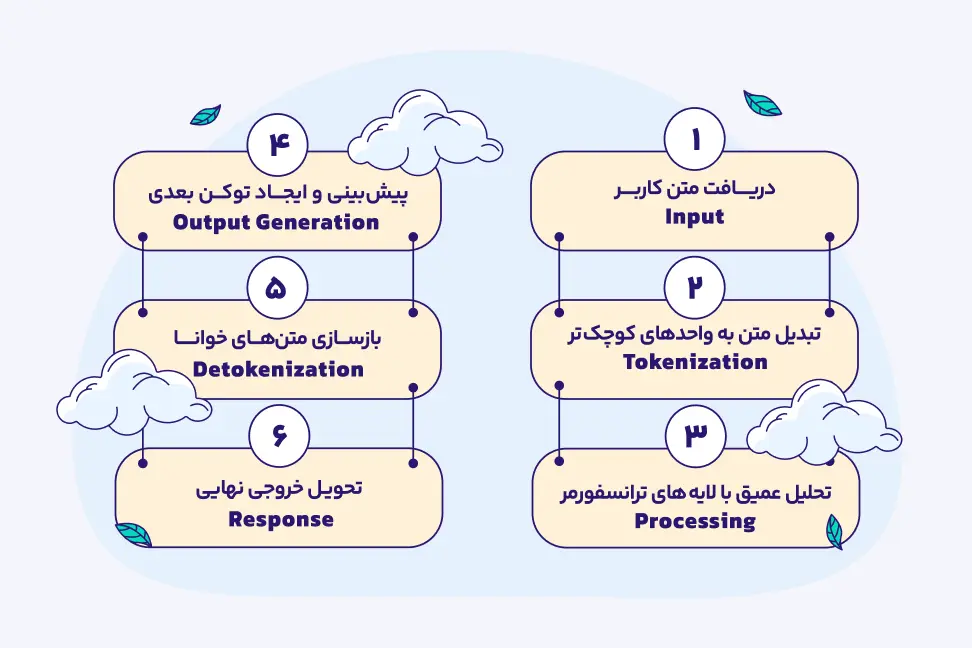
کارکرد یک مدل زبان بزرگ (LLM) را میتوان با شش گام اصلی توضیح داد که هر مرحله نقش مهمی در تولید پاسخ دقیق و طبیعی دارد.
۱. ورودی (Input)
همه چیز با ورود متن توسط کاربر شروع میشود. این متن میتواند یک سوال، دستور یا پرامپت ساده باشد. مدل باید ابتدا بفهمد که کاربر چه میخواهد و چه متنی را پردازش کند. این مرحله نوع دادهها را تعیین کرده و آنها را برای پردازش آماده میکند تا هدف نهایی مدل مشخص گردد.
۲. توکندار شدن (Tokenization)
متنی که وارد شد، نمیتواند به صورت مستقیم توسط مدل پردازش شود. بنابراین ابتدا به واحدهای کوچکتر به نام توکن تبدیل میشود. توکنها میتوانند کلمات، زیرکلمات یا حتی حروف باشند. این کار به مدل اجازه میدهد که متن را به صورت عددی و قابل پردازش بفهمد و الگوهای زبانی را بهتر شناسایی کند.
۳. پردازش (Processing)
در این مرحله تمامی توکنها به اعداد تبدیل شده و وارد بردار میشوند که به این مرحله embeddings میگویند. حالا با کمک شبکه ترنسفورمر (که در واقع یک شبکه عصبی با مهارت فهم ارتباطات بین بخشهای مختلف متن است) و مکانیزم توجه (attention) که تعیین کننده میزان اهمیت و اولویت هر یک از بخشهاست، به درک معنی و تحلیل متن میپردازد. به بیان سادهتر، مدل بهجای نگاه کردن به کلمات پشت سر هم، موقعیت و ارتباط واژهها را با هم میسنجد تا معنی کامل و دقیق متن را بفهمد و الگوهای پیچیده زبان را تشخیص دهد.
۴. تولید خروجی (Output Generation)
با استفاده از اطلاعات پردازش شده، مدل به صورت مرحلهبهمرحله توکن بعدی را پیشبینی میکند. این کار تا زمانی ادامه دارد که متن کامل شود. در این مرحله، متن تولیدی مدل براساس الگوها و آموزشهایی است که از دادههای قبلی یاد گرفته، بنابراین پاسخها شبیه متن انسانی و روان خواهند بود.
۵. از بین بردن توکنها (Detokenization)
توکنهای تولید شده باید دوباره به متن قابل خواندن برای انسان تبدیل شوند. این مرحله مانند ترجمه از زبان داخلی مدل به زبان طبیعی است و متن خروجی را به شکلی ارائه میدهد که کاربر بتواند آن را بفهمد و استفاده کند.
۶. پاسخ نهایی (Response)
در نهایت، متن تولید شده به عنوان پاسخ مدل به کاربر ارائه میشود. این پاسخ میتواند جواب سوال، ادامه متن یا راهنمایی باشد. در این مرحله، مدل به صورت نهایی متن را تحویل میدهد و چرخه تعامل با کاربر کامل میشود.
خرید سرور مجازی سریع و امن از پارسپک
با خرید سرور مجازی از پارسپک، دیگر نگران کندی یا اختلالات سیستم نباشید. سرورهای مجازی ما با منابع اختصاصی و پشتیبانی ۲۴ ساعته، تجربهای بینظیر از سرعت بالا، امنیت مطمئن و کنترل کامل به شما میدهند. این سرویس نهتنها برای وبسایتهای پربازدید، بلکه برای استارتاپها و کسبوکارهایی که به پایداری و مقیاسپذیری نیاز دارند، مناسب است.
کاربردهای عملی LLM در زندگی و کسبوکار
LLMها در سالهای اخیر نقش مهمی در سادهتر شدن زندگی روزمره و تحول کسبوکارها ایفا کردهاند. این مدلها با درک بهتر زبان انسان، انجام کارهای پیچیده را به صورت سریعتر و دقیقتر ممکن کردهاند؛ از کمک در تصمیمگیری گرفته تا تولید محتوا، پاسخگویی هوشمند، تحلیل داده، حتی همراهی در آموزش و درمان و… . نتیجه این تحول، ایجاد تجربههای کاربری بهتر، کاهش هزینهها و افزایش بهرهوری در بسیاری از فعالیتهای شخصی و حرفهای است. در ادامه، مهمترین صنایعی را بررسی میکنیم که بیشترین تغییر را با ورود LLM ها تجربه کردهاند.
۱. بازارهای مالی
در بازارهای مالی، مدلهای زبانی بزرگ حجم عظیمی از دادهها را تحلیل میکنند تا الگوهای بازار شناسایی شود، ریسکها ارزیابی شود و فعالیتهای مشکوک یا تقلبی تشخیص داده شود. این تواناییها به شرکتهای مالی کمک میکند که تصمیمهای سرمایهگذاری دقیقتری بگیرند و الزامات نظارتی را بهتر رعایت کنند.
۲. سلامت و درمان
LLMها در حوزه سلامت، وظایف زیر را انجام میدهند:
- تعامل با بیمار را سادهتر میکنند.
- فرایندهای اداری را مدیریت میکنند.
- در تشخیصها از طریق پردازش زبان طبیعی به پزشکان کمک میکنند.
- نتیجه این فرایند، ارائه خدمات بهتر و مدیریت کارآمدتر مراکز درمانی است.
۳. بازاریابی
تیمهای بازاریابی از LLMها برای تحلیل احساسات مشتریان، بررسی روندهای رفتاری و تولید محتوا استفاده میکنند. این فرایند باعث میشود کمپینها دقیقتر هدفگذاری شود، تجربه کاربران شخصیتر شود و نرخ تبدیل افزایش یابد.
۴. آموزش
در حوزه آموزش، مدلهای زبانی بزرگ تجربه یادگیری شخصیسازیشده ایجاد کرده و به معلمان کمک میکنند تا بازخورد لحظهای و مبتنی بر داده در مورد عملکرد دانشآموزان دریافت کنند. نتیجه این فرایند، بهبود محیط آموزشی و یادگیری موثرتر است.
۵. حوزه حقوقی
موسسات حقوقی از LLM ها برای جستوجوی اسناد، انجام تحقیقات حقوقی و تحلیل قراردادها استفاده میکنند. این کار زمان مورد نیاز برای بررسی پروندهها را به شکل چشمگیری کاهش میدهد.
۶. خدمات مشتری
سازمانهای فعال در حوزه خردهفروشی و تجارت الکترونیک از LLM ها برای اتوماسیون خدمات پشتیبانی استفاده میکنند. این مدلها امکان پاسخگویی ۲۴ ساعته فراهم میکنند، رضایت مشتری را افزایش و هزینههای پشتیبانی را کاهش میدهند.
مزایای LLM چیست؟
مدلهای زبانی بزرگ یا LLM ها امکانات گستردهای دارند که باعث میشود در بسیاری از حوزهها کاربردی و ارزشمند باشند. در ادامه، پنج مزیت اصلی این مدلها را بررسی میکنیم:
۱. درک طبیعی زبان
این مدلها میتوانند متن را با دقت تحلیل کنند، زمینه آن را تشخیص دهند، احساسات را شناسایی کنند و اصطلاحات محاورهای و اصطلاحات ویژه هر زبان را درک کنند. همچنین LLMها میتوانند اطلاعات پنهان یا غیرمستقیم را استنباط کنند و به پرسشهای مبهم پاسخ مناسب دهند.
۲. تولید چندرسانهای و چندجانبه
LLMها قادرند متن، اشعار، داستانها، ایمیلها، گزارشهای فنی و حتی زبان گفتاری را تولید کنند. با پیشرفت در چندرسانهای بودن، این مدلها فراتر از متن رفته و از صدا، تصویر و دیگر قالبهای رسانهای پشتیبانی میکنند.
۳. تولید و تحلیل کد
LLMها قادرند کدها را تولید یا تحلیل کنند. آنها میتوانند کدها، توابع یا حتی برنامههای کامل را بر اساس توضیحات طبیعی تولید کرده و آنها را اشکالزدایی کنند. همچنین راههایی برای بهینهسازی پیشنهاد داده و بخشهای پیچیده کد را توضیح دهند. این مدلها به توسعهدهندگان در زمینههای زیر کمک میکنند:
- ساخت برنامهها
- تکمیل خودکار کد
- شناسایی خطاها
- تحلیل و دیباگ نرمافزار
- ارائه پشتیبانی ۲۴ ساعته بدون خستگی
- تولید تستکیس بر اساس مشخصات تابع
- تولید بلوکهای کامل کد در زبانهای برنامهنویسی مختلف
- پیشنهاد الگوهای طراحی مناسب
- بهبود خوانایی و نگهداری کد
- شناسایی مشکلات امنیتی در زبانهای مختلف
۴. انجام وظایف خاص بدون نیاز به فاینتیونینگ
با داشتن حجم عظیمی از دانش، LLMها میتوانند وظایفی مانند خلاصهسازی، ترجمه، پاسخ به سوال و تولید کد را با آموزش حداقلی انجام دهند. همچنین امکان بهروزرسانی و بهبود عملکرد با دادههای جدید بهصورت دورهای فراهم میشود.
۵. مقیاسپذیری و کارایی
LLMها میتوانند محتوای بلند یا اسناد گسترده را همزمان پردازش و تحلیل کنند و با استفاده از GPU، سرعت آموزش و استنتاج را افزایش دهند. این قابلیت امکان مدیریت و تولید سریع پاسخ را فراهم میکند. با استفاده از LLM ها، افزایش حجم کاری و رشد نیازهای کسبوکار بهراحتی مدیریت میشود.
انواع مدلهای زبانی بزرگ یا LLM

تمام مدلهای زبانی بزرگ قادر به تولید و پردازش متن هستند، اما نوع معماری و روش آموزش آنها تفاوت ایجاد میکند. سه نوع رایج LLM شامل Decoder-only، Encoder-only و Encoder-Decoder هستند که در ادامه بیشتر در مورد هرکدام توضیح میدهیم:
۱. مدل Encoder-Only
این مدلها هدفشان فهم متن ورودی است و معمولا برای تحلیل و دستهبندی متنها استفاده میشوند، مثل تشخیص احساسات یا اینکه یک متن درباره چیست. در مدل Encoder-Only متن ورودی خوانده میشود و مدل سعی میکند مهمترین اطلاعات آن را بفهمد؛ مثلا کلمههای کلیدی یا ساختار معنایی جمله.
۲. مدل Decoder-Only
مدل Decoder-Only در تولید متن قوی هستند. این مدل برای ساختن متن، چتباتها، پاسخگویی به سوالات و نوشتن داستان استفاده میشود.
۳. مدل Encoder-Decoder
این مدلها بخش اول متن را «میفهمد» و سپس بخش دوم آن را «میسازد»، بنابراین هم میتواند معنی ورودی را بهتر تحلیل کند و هم خروجی دقیقتری بدهد. این مدل برای کارهایی مثل ترجمه، خلاصهسازی یا پاسخهایی وابسته به متن ورودی بسیار مناسب است، چون مدل ورودی را کاملا میفهمد و بعد خروجی میسازد.
مقایسه سریع انواع LLM
| نوع مدل | نقاط قوت | مثالهای معروف | کاربرد اصلی |
|---|---|---|---|
| Encoder-only | درک عمیق متن و زمینه، پردازش دوطرفه | BERT, RoBERTa, DistilBERT | تحلیل احساسات، جستوجو در متن، خلاصهسازی اطلاعات |
| Decoder-only | تولید متن خلاقانه، مقیاسپذیری بالا، مدیریت گفتگوهای طولانی | GPT-3, GPT-4, LLaMA, Falcon | نوشتن متن، کدنویسی، پاسخ به سؤالها، تولید محتوا |
| Encoder-Decoder | ترکیب تحلیل و تولید متن، وظایف متن به متن، ترجمه و خلاصهسازی | T5, FLAN-T5, mT5 | ترجمه، خلاصهسازی، پاسخ به پرسشها، تبدیل متن به متن |
مثالهای معروف LLM که هر روز با آن سروکار دارید!
مدلهای زبانی بزرگ یا LLMها امروز در زندگی روزمره و کسبوکار کاربردهای گستردهای دارند و شرکتها و کاربران شخصی هر روز با آنها تعامل دارند. در ادامه، مهمترین و شناختهشدهترین مدلها را معرفی کرده و ویژگیها و کاربردهایشان را توضیح میدهیم.
ChatGPT (OpenAI)
اگر این سوال برایتان پیش آمده که نوع مدل مورد استفاده در چت جی پی تی چیست؟ باید بگوییم مدل آن Decoder-only است. ChatGPT یکی از شناختهشدهترین مدلهای LLM است که توانایی تولید متن، پاسخدهی به سوالات، خلاصهسازی محتوا و حتی برگزاری گفتگوهای طبیعی با کاربران را دارد.
Grok (xAI)
این مدل دارای دو حالت Think Mode و DeepSearch Mode است، همچنین مدل زبانی آن هم مانند Chatgpt، Decoder-only است. Grok در مسائل ریاضی و استدلال عملکرد بسیار خوبی دارد و از Rust و Python برای آموزش استفاده میکند.
Gemini (Google)
Gemini جایگزین Palm و Bard شده و تصاویر، صدا، ویدئو و متن را پردازش میکند. به همین دلیل هم از مدل Decoder-only استفاده مینماید. برای آشنایی بیشتر با نحوه کار Gemini مطلب برنامه gemini چیست؟ را بخوانید.
DeepSeek
DeepSeek-R1 یک مدل استدلالی است که مسائل پیچیده ریاضی و منطقی را حل میکند. نسخه V3.1 امکان تغییر بین حالتهای تفکر و استدلال را فراهم میکند و سرعت و پیچیدگی پاسخها را بهبود میبخشد. این ابزار از مدل Decoder-Only استفاده میکند.
چالشها و محدودیتهای LLM و راهحلهای آن
هرچند LLM ها قدرتمند هستند، اما محدودیتها و چالشهایی نیز دارند که در جدول زیر بررسی میکنیم:
| چالشها و مشکلات | توضیح | راهحلها |
|---|---|---|
| توهم پاسخها (Hallucinations) | مدلها پاسخها را پیشبینی میکنند، نه از واقعیت. ممکن است اطلاعات نادرست با اعتماد بالا ارائه دهند. | استفاده از RAG، اجباری کردن ارجاع به منابع، خروجی ساختاریافته و کنترل اعتبار |
| تزریق پرامپت (Prompt Injection) | کاربران یا اسناد مخرب میتوانند مدل را فریب دهند و قوانین سیستم را دور بزنند. | سیستم پرامپت سخت، پاکسازی ورودیها، تفکیک واضح دستورات سیستم و دادهها، محدود کردن دسترسی و دستورات خواندنی فقط |
| محدودیت حافظه زمینهای (Context Window Limits) | مدل تنها میتواند مقدار محدودی متن را همزمان پردازش کند؛ بخشهای قدیمی فراموش میشوند. | تقسیم هوشمند متن به بخشهای کوچک با همپوشانی، بازیابی فقط بخشهای مرتبط (RAG)، مدیریت حافظه مکالمه و خلاصهسازی، افشای تدریجی اطلاعات |
| عدم قطعیت پاسخها (Non-Determinism) | مدل برای یک سوال یکسان میتواند جوابهای متعددی به صورت تصادفی ایجاد کند. | پین کردن نسخه مدل، ثبت کامل لاگها، استفاده از پارامتر seed |
| هزینه و تاخیر بالا (Cost & Latency) | مدلها گران و کند هستند؛ تعداد کاربران و توکنهای زیاد، هزینه را افزایش میدهد. | بهینهسازی پرامپت و کاهش توکنها، استفاده از مدلهای چندسطحی (Budget/Mid/Premium)، کشینگ پرامپت و پاسخها، پردازش موازی و نمایش تدریجی، محدودیتهای زمانی و تعداد توکن |
| سوگیری و انصاف (Bias & Fairness) | مدلها با توجه به دادههای انسانی موجود ممکن است سوگیری داشته باشند. | استفاده از مجموعه دادههای ارزیابی متنوع، معیارهای سنجش سوگیری، محدودیتهای عدالت و بازبینی انسانی، ممیزیهای دورهای و بررسی بازخورد کاربران |
| حریم خصوصی و نشت داده (Privacy & Data Leakage) | ممکن است اطلاعات حساس کاربر یا دادههای آموزش را افشا کند؛ خطر قانونی و امنیتی. | شناسایی و حذف PII، جداسازی دادهها و پایان جلسه، سیاستهای نگهداری داده و کنترل کاربر، مطابقت با GDPR/HIPAA/CCPA و ممیزیها |
| محدودیتهای استدلال (Reasoning Limitations) | مدلها در محاسبات دقیق، منطق چندمرحلهای و استدلال زمانی محدود هستند؛ ممکن است پاسخهای ناقص یا غلط بدهند. | استفاده از ابزارها و توابع خارجی (ماشین حساب، تقویم، قوانین سازمان)، Chain-of-Thought (CoT)، خروجی ساختاریافته، لایه اعتبارسنجی و قوانین صریح در پرامپت |
آینده LLM چیست؟ چه تغییراتی در انتظار ما است؟
با اینکه پیشبینی آینده دشوار و شاید غیرممکن است، تحقیقات زیادی روی LLMها انجام میشود که هدف اصلی آن رفع مشکلاتی است که هنوز هنگام استفاده از این مدلها با آنها مواجه میشویم. بیایید نگاهی به سه تغییر مهم که پژوهشگران روی آنها کار میکنند بیندازیم.
۱. بررسی خودکار صحت اطلاعات: یکی از مهمترین روندها، افزایش دقت واقعی LLM ها با امکان بررسی صحت پاسخها توسط خود مدل است. این قابلیت به مدلها اجازه میدهد از منابع خارجی استفاده کنند و ارجاعات و منابع معتبر ارائه دهند. ابزارهای زیر نسبتا دادهها و نتایج قابل اتکایی دارند:
- REALM از گوگل
- RAG از فیسبوک
- WebGPT از OpenAI
هر آنچه که درباره RAG نمیدانستید را در مقاله زیر بخوانید:
۲. نیاز به مهندسان پرامپت حرفهای: با اینکه LLMها پیشرفت زیادی کردهاند، هنوز در درک کامل زبانها از انسانها عقب هستند و ممکن است در تولید متن اشتباهاتی داشته باشند. مهندسان پرامپت با طراحی پرامپتهای هوشمند، میتوانند مدل را هدایت کنند تا پاسخهای دقیقتر و مرتبطتری ارائه دهد. روشهایی مانند Few-Shot Learning و Chain of Thought Prompting نمونههای موثر برای تولید پاسخهای صحیح و منطقی هستند.
۳. بهبود روشهای تنظیم دقیق و همراستایی: تنظیم دقیق LLMها با دادههای تخصصی، عملکرد آنها را بهطور قابل توجهی بهبود میبخشد. روشهایی مانند RLHF (یادگیری تقویتی از بازخورد انسانی) به مدل کمک میکنند تا با اهداف کاربران همراستا شود و پاسخهای واقعیتر و قابل اعتماد ارائه دهد. این روش یکی از دلایل موفقیت ChatGPT4 در پیروی از دستورات است.
جمعبندی
مدلهای زبانی بزرگ یا LLMها، با پشتوانه دادههای گسترده و معماریهای پیشرفته مانند ترنسفورمر، توانستهاند مرزهای تعامل انسان و ماشین را جابهجا کنند. از تولید متن طبیعی و پاسخهای هوشمند گرفته تا تحلیل داده و کدنویسی، کاربردهای آنها روزبهروز گستردهتر میشود. با این حال، چالشهایی مانند توهم پاسخ، محدودیت حافظه و سوگیری همچنان وجود دارد که پژوهشگران و توسعهدهندگان در تلاشند آنها را رفع کنند.
آینده LLMها نویدبخش مدلهایی دقیقتر، قابل اعتمادتر و هوشمندتر است که با کمک مهندسان پرامپت حرفهای و روشهای پیشرفته همراستایی، تجربهای طبیعی و انسانیتر در تعامل با هوش مصنوعی فراهم میکنند. در نهایت، LLMها نه تنها ابزارهایی برای تسهیل کارهای روزمره هستند، بلکه به موتور محرکی برای نوآوری، خلاقیت و رشد کسبوکارها تبدیل شدهاند.
سوالات متداول
تفاوت LLM با مدلهای ترنسفورمر معمولی چیه؟
LLMها ترنسفورمرهایی هستند که با دادههای بسیار بزرگتر آموزش دیدهاند و توانایی درک و تولید زبان طبیعی در مقیاس وسیعتری دارند.
LLM در کسبوکار ایرانی چطور استفاده میشود؟
برای تولید محتوا، پشتیبانی مشتری، تحلیل دادههای متنی، ساخت چتبات و افزایش سرعت انجام کارهای روزمره استفاده میشود.
مزایای اصلی LLM برای بهرهوری چیست؟
باعث کاهش زمان انجام کارها، خودکار سازی وظایف متنی و افزایش دقت در تصمیمگیری و تولید محتوا میشود.
آینده مدلهای زبانی بزرگ در ایران چطور است؟
با رشد استارتاپها و بومیسازی هوش مصنوعی، استفاده از LLM ها در آموزش، کسبوکار و خدمات دیجیتال گسترش خواهد یافت.